![[인공지능][개념&실습] 트리의 앙상블(Ensemble)[1] - 랜덤 포레스트(Random Forest)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FC5uFQ%2Fbtq5fx7m8g4%2FAAAAAAAAAAAAAAAAAAAAAKAMaI2xcRz9yuriIprMYlDjCYORgpCFEw0J7DZWfF-f%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DjgFDxKAx5L9QjwpUHhMP%252Flgi%252FI0%253D)
결정 트리(Decistion Tree)와 가지치기(Pruning)에 대한 이론이 필요하신 분들은 아래 링크를 참조해주시기 바랍니다.
[인공지능][개념] 분류(Classification) - 결정 트리(Decisioin Tree)와 가지치기(Pruning) : https://itstory1592.tistory.com/12
[인공지능][실습] 결정 트리(Decision Tree) 모델로 와인(Wine) 데이터셋을 분류하고 교차 검증(Cross Validation)과 그리드 서치(Grid Search)로 최적의 하이퍼 파라미터를 찾아보자! : https://itstory1592.tistory.com/13
앙상블 (Ensemble)

앙상블(Ensemble)은 통계역학에서, 어떤 계와 동등한 계의 모음을 말한다.
어렵게 들릴 수도 있겠지만, 이름과 연관 지어 해석하면 비슷한 무리들의 집합체라고 이해할 수 있다.
즉, 한 가지 단일 모델에서 나오는 결과를 얻는 것에 집중하는 것이 아니라,
여러 단일 모델들의 결과를 평균 내거나(회귀), 투표를 통해 다수결에 의한 결정(분류)을 하는 등
'여러 모델들의 집단 지성'을 활용하여 더 나은 결과를 도출해 내는 것에 주목적이 있다.
그렇다면 트리의 앙상블이란 무엇일까?
위에서 설명했듯이, 앙상블은 하나의 모델이 아닌, 여러 개의 동등한 모델에서 나온 결과를 종합한 것이다.
따라서 트리의 앙상블(Ensemble of trees)은, 여러 무리의 결정 트리(Decision Tree)를 종합하여
최선의 결과를 얻어내는 기법이라고 할 수 있다.
우리는 이전 시간에 결정 트리의 과대 적합(Overfitting)을 해결하기 위해 트리의 최대 깊이(max_depth)를 설정하며 가지치기를 해보았다.
하지만, 가지치기만으로는 모델의 과대적합을 충분히 해결할 수는 없다.
그래서 등장한 기법이 바로 랜덤 포레스트이다.
(결정 트리의 앙상블에는 여러 종류의 기법이 있지만, 이번 글에서는 랜덤 포레스트만 다룰 예정이다.)
랜덤 포레스트(Random Forest)
랜덤 포레스트(Random Forest)는 '데이터셋에서 중복을 허용하여 무작위(Random)로 N개의 데이터를 선택'한다.
(이 과정을 부트스트랩(Bootstrap)이라고 부른다.)
모델은 부트스트랩을 K번 동안 반복하여 훈련하게 되는데, 이 과정에서 생성된 결정 트리(Decision Tree) K개를 이용하여,
결과의 평균이나 가장 많이 등장한 값을 최종 예측값으로 결정한다.
회귀(Regression)에서는 최종 예측값으로 위의 결과를 평균하여 사용하며, 분류(Classification)에서는 빈번히 나온 결과를 사용한다.
실습을 통해 랜덤 포레스트 모델을 직접 사용해보자.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
이전 예제와 동일하게 와인 데이터셋을 불러주고, 특성(feature)과 타겟(target)을 각각 다른 변수에 저장해준다.
그러고 나서 train_test_split() 메소드를 사용하여 훈련용 데이터셋과 테스트용 데이터셋을 8 : 2로 나누어준다.
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
랜덤 포레스트(Random Forest)를 사용하기 위해서는,
사이킷런(sklearn)에서 제공하는 RandomForestClassfier를 임포트 해주면 된다.
해당 예제에서는 교차 검증(Cross Validation)을 해보고,
return_train_score를 True로 설정하여 훈련 점수도 출력해보도록 하자.

결과를 살펴보면 모델이 훈련세트에 다소 과대 적합된 모습을 볼 수 있다.
참고로 랜덤 포레스트는 결정 트리의 앙상블이기 때문에 DecisionTreeClassifier와 동일하게,
criterion, max_depth, max_features, min_samples_split, min_impurity_decrease, min_samples_leaf 등 다양한 매개변수를 제공한다.
(GridSearch를 통해 과대적합을 극복할 수 있지만, 이 글의 예제가 매우 간단하고 특성이 많지 않아 결과 변동이 크게 없으며, 랜덤 포레스트가 무엇인지 알아보는 것이 목적이므로 따로 하이퍼 파라미터를 튜닝하지는 않는다.)
rf.fit(train_input, train_target)
print(rf.feature_importances_)
결정 트리(Decision Tree)의 장점 중 하나인 특성 중요도를 출력해보고,
랜덤 포레스트와 결정 트리의 특성 중요도 차이를 살펴보도록 하자.
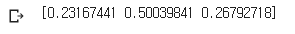 |
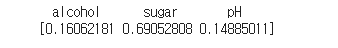 |
왼쪽이 랜덤 포레스트 모델에서의 특성 중요도이고 오른쪽이 결정 트리에서의 특성 중요도이다.
랜덤 포레스트에서는 sugar의 중요도가 살짝 낮춰지고, alcohol과 pH의 중요도가 다소 높아진 모습을 볼 수 있다.
이런 이유는 랜덤 포레스트가 특성의 일부를 랜덤하게 선택하여 훈련하기 때문인데,
그 결과 하나의 특성에 과도하게 집중하지 않고 조금 더 많은 특성이 훈련에 기여할 기회를 얻는 것이다.
이는 곧 과대 적합을 줄이고, 일반화 성능을 높이는데 도움이 된다.
#oob : out-of-bag
#부트스트랩 샘플링시 선택되지 않은 데이터
#oob를 True로 설정하면 oob 샘플을 기반으로 평가할 수 있다.
rf = RandomForestClassifier(oob_score=True, n_estimators=1000, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_)
마지막으로, oob_score를 True로 설정하여, 랜덤 포레스트에게 OOB샘플로 모델을 평가하여 점수를 반환해달라고 해보자.
OOB는 부트스트랩(BootStrap) 샘플에 포함되지 않고 남는 샘플 데이터이다.
이 남는 샘플을 사용하여, 마치 검증 세트처럼, 훈련한 결정 트리 모델을 평가할 수 있는 것이다.

교차 검증에서 얻은 훈련 점수와 비슷한 결과를 얻었다.
OOB 점수를 사용하면 교차 검증을 대신할 수 있기 때문에, 훈련 세트에서 더 많은 샘플을 사용할 수 있다는 점이다.
전체 소스 코드 :
(이해가 다소 힘들거나, 틀린 부분이 있다면 댓글 부탁드리겠습니다! 😊)
💖댓글과 공감은 큰 힘이 됩니다!💖