![[인공지능][실습] 결정 트리(Decision Tree) 모델로 와인(Wine) 데이터셋을 분류하고 교차 검증(Cross Validation)과 그리드 서치(Grid Search)로 최적의 하이퍼 파라미터를 찾아보자!](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FconAck%2Fbtq45NQzatq%2FAAAAAAAAAAAAAAAAAAAAAMhJbWjrJBTx94XngOTwyoxSpte-k_B3kAl6W68e-BmC%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DEVhCV9Vq8Mz1P9UVbJOPCT2dIPI%253D)
결정 트리(Decistion Tree)와 가지치기(Pruning)에 대한 이론이 필요하신 분들은 아래 링크를 참조해주시기 바랍니다.
[인공지능][개념] 분류(Classification) - 결정 트리(Decisioin Tree)와 가지치기(Pruning) : https://itstory1592.tistory.com/12


이번 글에서는 결정 트리(Decision Tree)와 가지치기(Pruning)를 사용하여 모델의 과대 적합(Overfitting)을 줄이면서 와인 데이터셋을 화이트 와인과 레드 와인으로 분류하는 모델을 구현해볼 예정이다.
더불어 교차 검증(Cross Validation)을 통해 테스트 데이터 한 묶음만 사용하는 것이 아닌, 훈련용 데이터의 모든 부분을 테스트 데이터로 활용하는 방법과, 그리드 서치(Grid Search)로 최적의 하이퍼 파라미터를 찾아보는 방법에 대해 알아보자.
이전 실습에서는 로지스틱 회귀(Logistic Regression) 모델을 이용하여 데이터를 분류하는 방법에 대해 배웠는데,
왜 결정 트리 (Decision Tree)를 알아야 할까?
이유를 알기 위해, 우선 로지스틱 회귀 모델로 와인 데이터셋을 학습시켜보자.
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
wine.head()
우선 판다스(pandas) 라이브러리를 통해 와인 데이터셋을 불러오고,
맨 위에 위치한 와인 데이터 5개를 출력해보자.
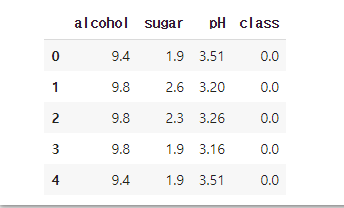
특징(feature)으로는 alcohol(도수), 당도(sugar), pH(산성)이 있다.
맨 오른쪽에 있는 class는 화이트 와인과 레드 와인을 숫자로 표현한 것인데,
이 데이터에서는 class가 0인 데이터가 화이트 와인, 1인 데이터를 레드 와인으로 표현하였다.
wine.info()
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
다음으론, info() 메소드를 호출하여 데이터의 구성을 더 구체적으로 확인해보고,
모델 훈련을 위해, 데이터 구성을 '입력 데이터(input data)'와 '타겟 데이터(target)'로 나누어 준다.

총 6497개의 데이터가 존재하며, null 값이 없어 따로 처리할 필요는 없을 것 같다.
컬럼(특징)은 위에서 봤던 것처럼 alcohol, sugar, pH가 존재한다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
print(train_input.shape, test_input.shape)
이제 train_test_split() 메소드를 통해 전체 데이터를 훈련용 데이터셋과 테스트용 데이터셋으로 나누고,
실제로 데이터가 잘 나누어졌는지 출력해보자.

3개의 컬럼(Column)으로 이루어진 데이터가 대략 8 : 2 비율로 데이터가 적절히 나누어진 모습을 확인할 수 있다.
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
#표준 스케일러
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
print('\n')
print(lr.coef_, lr.intercept_)
데이터 처리가 끝났다면 본격적으로 로지스틱 회귀를 사용하기 위해 사이킷런(sklearn)의 LogisticRegression 클래스를 임포틀해준다.
로지스틱 회귀에서는 각각의 특징(alcohol, sugar, pH)들의 데이터 스케일이 다르므로, StandardScaler()를 통해 데이터를 표준화해주어야 한다.
이러한 과정을 데이터 전처리(Data Scaling)라고 부른다.
이 과정을 마쳤다면, 로지스틱 회귀 모델을 선언하여 fit() 메소드를 통해 훈련용 데이터셋을 훈련시킨다.
그다음에는, 과대(Overfitting), 과소적합(Underfitting) 여부를 확인하기 위해 훈련용 데이터셋과 테스트용 데이터셋의 점수를 출력시켜보고,
각 특징들 중에서 어떤 특징이 모델에서 중요한 역할을 하는지 확인해보기 위해, 훈련시킨 모델의 coef_와 intercept_에 접근하여 가중치와 절편을 분석해보자.

훈련용 데이터셋과 테스트용 데이터셋에 대해 모두 78% 정도의 정확도가 출력되었다.
이전에 비해 그리 높은 정확도는 아닌 듯하다.
그 밑에는 각각 alcohol, sugar, pH 순으로 가중치와 절편이 출력되었는데,
알코올(alcohol)과 당도(sugar)와 가중치가 양수인 것으로 보아, 알코올과 당도가 클수록 양성 클래스(화이트 와인)일 가능성이 높아지고, 맨 오른쪽에 있는 pH가 클수록 음성 클래스(레드 와인)일 가능성이 높을 것이라고 예상할 수 있다.
해당 가중치와 절편으로 만든 Z 방정식의 값이 0보다 크면 양성 클래스, 0보다 작으면 음성 클래스로 분류된다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
로지스틱 회귀 모델로 학습이 마쳤다면, 이제 오늘 본문의 주인공인 결정 트리(Decision Tree) 모델을 훈련시켜보자.
결정 트리도 이전과 다를 바 없이 DecisionTreeClassifer로 인스턴스를 생성해주고 fit() 메소드로 훈련용 데이터셋을 학습시키면 된다.
다른 점으로는, 결정 트리는 로지스틱 회귀와 달리 데이터 전처리(Data Scaling) 과정이 필요 없다는 점이다.
결정 트리는 개별적인 특성을 기준으로 데이터에게 질문을 던져 분류하기 때문이다.
학습을 마친 후 훈련 데이터와 테스트 데이터의 점수를 확인해보면..?!

로지스틱 회귀 모델에 비해 정확도가 확연히 높아졌음을 알 수 있다.
하지만, 훈련 데이터에 대한 점수가 상대적으로 너무 높기 때문에 이 모델은 훈련 데이터에 과대적합(Overfitting) 되었다고 할 수 있다.
한번 해당 모델에 대한 모양을 그림으로 나타내어 확인해보자.
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
맷플롯립(matplotlib)과 사이킷런(sklearn)에서 결정 트리를 그림으로 표현하기 위해 필요한 라이브러리를 임포트해준다.
plt.figure()의 매개변수로 사용된 figsize는 차트의 그림 사이즈를 조정하는 변수이다.
(이 예제에서는 값을 (10, 7)로 설정하였다.)
plot_tree() 메소드는 매개변수로 전달받은 결정 트리 모델을 이미지로 표현해주는 역할을 한다.

show() 메소드를 호출하면 위와 같은 그림이 출력된다.
그림을 보면 알다시피, 결정 트리에 너무 많은 가지(branch)가 존재하는데,
이런 부분이 '과대 적합(Overfitting)의 요인'이 될 수 있다.
따라서, 우리는 가지치기(Pruning)라 불리는 기술을 통해 결정 트리의 깊이(depth)를 적절히 조절해줄 필요가 있다.
그전에, 이렇게 복잡한 트리 이미지가 실제로는 어떻게 생겼는지 살펴보자.
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
위에서 봤던 트리(tree) 이미지를 조금 더 보기 쉽게, max_depth를 1로 설정하여 깊이(depth)를 1까지만 그려보겠다.
매개변수 filled를 True로 설정해주면 클래스의 비율에 따라 노드(Node) 색상을 다르게 칠해준다.
(클래스 비율이 높을수록 Node의 색이 진해지며, 비율이 낮을수록 옅어진다.)

오른쪽 자식 노드 (Right Child Node)를 확인해보면 양성 클래스(레드 와인)의 개수가 훨씬 많기 때문에,
다른 노드들에 비해 진한 색상을 띠고 있음을 확인해볼 수 있다.
이제, 가지치기를 사용하여 이 복잡하고 과대적합한 결정 트리를 최적화시켜주자.
가지치기(Pruning)
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
가지치기(Pruning)라고 해서 그리 어려울 것이 없다.
기존 DecisionTreeClassifier에 max_depth를 3으로 설정해주어, 최대 뻗을 수 있는 가지의 깊이를 3으로 제한해주면 가지치기 작업이 끝이 난다.

그럼 이렇게 84%의 정확도를 가지면서 과대적합까지 해결된 모습을 확인할 수 있다.
이 결정 트리도 그림으로 나타내 보자.
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
위 코드로 인해, 깊이(Depth)가 3인 결정 트리가 출력되었다.
확실히 보기도 좋으면서, 과대적합까지 해결할 수 있어 1석 2조이다.
시각화를 해본김에 중요도까지도 수치로 확인해보자.
#특성의 중요도 출력
print(' alcohol sugar pH')
print(dt.feature_importances_)
coef_와 intercept_와 다르게 feature_importances_를 출력하면 각 특성(feature)의 중요도를 알아볼 수 있다.

coef_에 접근했을 때, 당도(sugar)의 가중치가 높게 나왔듯이, 중요도(importance) 또한 당도에서 확연히 높은 수치를 보여주고 있다.
dt = DecisionTreeClassifier(criterion='gini', min_impurity_decrease=0.0005, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
과대적합(overfitting)은 매개변수 max_depth를 조정하는 것 외에도, min_impurity_decrease를 조정하여 해결할 수도 있다.
매개변수 min_inpurity_decrease는 최소 불순도를 조절하여 트리를 구성하는데, 이 모델에는 0.0005라는 수치를 줘보겠다.
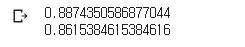
기존보다 과대적합이 해결됨과 동시에, max_depth를 조절했을 때보다 정확도가 약간 높아졌지만,
min_impurity_decrease를 조절했을 때는 과대적합이 완전히 해결되지는 않았다.
plt.figure(figsize=(20,15), dpi=300)
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
이유를 살펴보기 위해, 트리(tree)를 시각화하여 확인해보자.

최소 불순도(min_impurity)만 조절하다 보니 가지(branch)의 깊이가 꽤나 깊어졌기 때문인 듯하다..
그럼 최소 불순도와 최대 깊이를 동시에 적절히 조절해보면 되지 않을까?
하지만 '적절히' 라는 단어만큼 애매하고 어려운 것이 없다.
과연 몇으로 설정해야 적절한 값이 될 수 있을까?
머신러닝에서는 모델이 아닌 사람이 직접 지정해줘야 하는 매개변수를 하이퍼 파라미터(Hyper Parameter) 라고 부른다.
이 글에서 등장한 min_impurity_decrease와 max_depth 또한 마찬가지로 하이퍼 파라미터라고 할 수 있다.
사이킷런(sklearn)에는, 여러 값들 중에 어떤 값이 하이퍼 파라미터에 가장 적합한지 골라주는 'AutoML'클래스가 있다.
바로 'GridSearchCV'이다.
GridSearchCV는 교차 검증(Cross Validation)과 동시에 적절한 하이퍼 파라미터(Hyper Parameter) 값을 골라주는 유용한 클래스이다.
잠깐! 교차검증(Cross Validation)이란?
교차 검증(Cross Validation)은 전체 데이터의 1/k을 k번만큼 테스트 데이터로 사용하여 교차적으로 모델을 검증하는 방법이다.
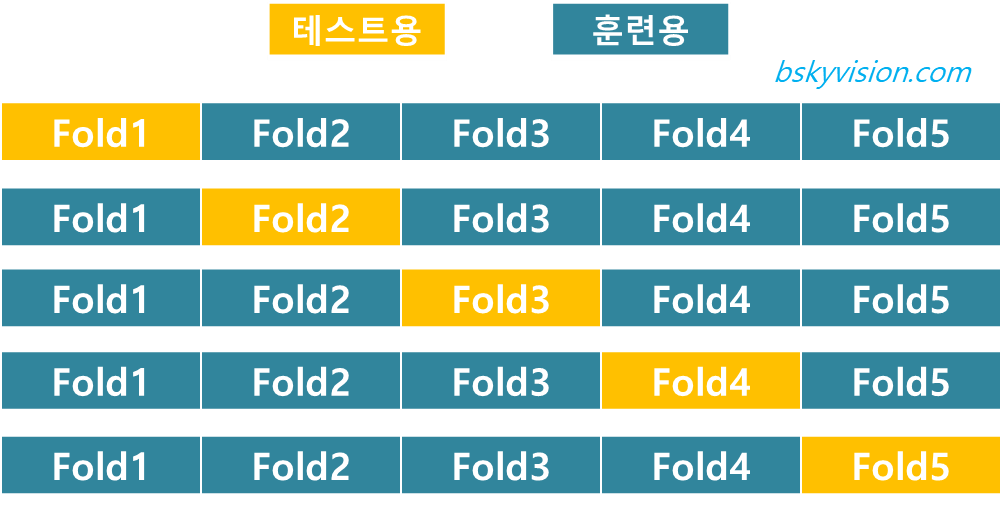
위 그림처럼, 전체 데이터의 1/5을 순차적으로 테스트용 데이터로 사용하는 방식이다.
만약 그림처럼 5 분할하여 사용하는 경우에는 5-폴드 교차 검증(5-Fold Cross Validation)이라고 부르며,
보통, 5-폴드 교차 검증 또는 10-폴드 교차 검증을 많이 사용한다.
교차 검증을 하는 이유는, 모델을 테스트함에 있어, 테스트용 데이터셋만 사용하게 되면, 모델이 테스트 데이터셋에 'Overfit'하는 경우가 발생하기 때문이다.
또는 훈련 데이터가 부족할 경우, 전체 데이터의 1/k을 k번만큼 반복하여 테스트 데이터로 사용하면 모든 데이터를 테스트에 사용할 수 있다는 장점이 있다.
교차 검증의 장단점에 대해 보기 쉽게 정리해 놓았다.
교차 검증 장점 :
1. 모든 데이터 셋을 평가에 활용할 수 있다.
- 평가에 사용되는 데이터 편중을 막을 수 있다. (특정 평가 데이터 셋에 overfit 되는 것을 방지할 수 있다.)
- 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다.
2. 모든 데이터 셋을 훈련에 활용할 수 있다.
- 정확도를 향상시킬 수 있다.
- 데이터 부족으로 인한 과소 적합(underfitting)을 방지할 수 있다.
교차 검증 단점 :
1. Iteration 횟수가 많기 때문에 모델 훈련/평가 시간이 오래 걸린다.
from sklearn.model_selection import GridSearchCV
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)
}
# min_impurity_decrease : 최소 불순도
# min_impurity_split : 나무 성장을 멈추기 위한 임계치
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_)
dt = gs.best_estimator_
print(dt.score(test_input, test_target))
params라는 딕셔너리 변수의 Key값으로는 우리가 설정할 하이퍼 파라미터 명칭을 입력하고,
Value로는 하이퍼 파라미터의 범위를 설정해준다.
GridSearchCV 클래스의 매개변수로는 우리가 사용할 모델과 위에서 선언한 params을 매개변수로 입력해주면 된다.
우리는 결정 트리(Decision Tree) 모델을 그리드 서치 및 교차 검증할 것이기 때문에, DecisionTreeClassifier 모델을 사용한다.
모델의 훈련을 마친 후에는 최적의 파라미터를 best_params_에 접근하여 알아볼 수 있으며,
이 파라미터를 사용하여 훈련된 모델을 best_estimator_에 접근하여 얻을 수 있다.

max_depth는 14 / min_impurity_decrease는 0.0004, min_samples_split은 12가 가장 적절하다고 말해주고 있다.
테스트셋에 대한 점수는 0.86 정도로 꽤 높은 편이다.
오늘은 결정 트리(Decision Tree)와 가지치기(Pruning)를 통해 분류 모델을 훈련시켜 보았다.
결정 트리는 로지스틱 회귀 모델과 달리, 시각화했을 때 모델이 분류하는 기준을 눈으로 확인할 수 있었으며,
독립적인 특징(Independent feature)을 기준으로 연속된 질문을 던져 최종적으로 클래스를 분류하는 방식을 사용하였다.
이러한 방식 덕분에 데이터 전처리(Data Scaling) 또한 생략할 수 있다는 장점이 있었다.
(또한, 경우에 따라 다르겠지만 해당 예제에서는 로지스틱 회귀에 비해 결정 트리에서 점수가 더 높게 나왔다.)
그 외에도 하이퍼 파라미터로 어떤 값을 입력해야 할지 모르겠다면, 그리드 서치(Grid Search)를 사용하여 적절한 값을 찾아보아야 한다.
모든 훈련 데이터를 테스트 데이터셋으로 사용하고 싶으면, 교차 검증(Cross Validation)을 통해 1/n만큼의 데이터씩 테스트 데이터로 돌려가며 사용하면 된다는 것을 알 수 있었다.
전체 소스 코드 :
https://colab.research.google.com/drive/1rOVockfQZpNuL8fqR73mVZzSqgmkPqo7
(이해가 다소 힘들거나, 틀린 부분이 있다면 댓글 부탁드리겠습니다! 😊)
💖댓글과 공감은 큰 힘이 됩니다!💖