![[인공지능][실습] 순환 신경망(SimpleRNN) 모델로 IMDB 리뷰 감성 분류하기 - (원핫인코딩, 단어 임베딩)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FEG1lp%2Fbtq7SMIoJwr%2FAAAAAAAAAAAAAAAAAAAAAALFW4mHd0VrdsxojnrL7nP5ztV6jSqbE6EApYE-DSXz%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DHcDBiqILtCNLOao6y7%252BJ0ihxCkw%253D)
순환 신경망(RNN)에 대한 이론이 필요하신 분들은 아래 링크를 참조해주시기 바랍니다.
[인공지능][개념] 순환 신경망(Recurrent Neural Network) - RNN 모델 완전 정복하기 : https://itstory1592.tistory.com/36

이번 포스팅에서는 지난 글에 이어서 순환 신경망으로 IMDB 리뷰 데이터셋을 훈련시키고,
리뷰가 긍정적인지 부정적인지 감성을 분석하는 모델을 만들어보도록 하자.
IMDB 리뷰 데이터셋은 유명한 인터넷 영화 데이터베이스인 imdb.com 사이트에서 수집한 리뷰를
감상평에 따라 긍정과 부정으로 분류해 놓은 데이터셋이다.
총 50,000개로 이루어져 있고 훈련, 테스트 데이터에 따라 각각 25,000개씩 나누어져 있다.
이 데이터셋을 두 가지 방법으로 변형하여 순환 신경망에 주입해보겠다.
하나는 원-핫 인코딩(One-Hot Encoding)이고, 또 다른 하나는 단어 임베딩(Word Embedding)이다.
이 방법들에 대해서는 직접 실습을 해보면서 알아보도록 하자.
from tensorflow.keras.datasets import imdb
(train_input, train_target), (test_input, test_target) = imdb.load_data(
num_words=500)
우선, 데이터셋을 가져오기 위해 imdb 모듈을 임포트하여 데이터를 적재한다.
이때, num_words 매개변수를 500으로 설정하여 자주 등장하는 단어를 500개만 사용하자

그럼 이런 출력 결과가 나타나면서 데이터가 정상적으로 다운로드되는 모습을 확인할 수 있다.
#훈련세트와 테스트 세트의 개수 출력
print(train_input.shape, test_input.shape)
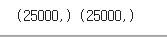
그 다음, 위 코드를 실행하여 훈련 데이터셋과 테스트 데이터셋의 크기를 출력해보면
처음 도입 부분에서 언급했듯이 각각 25,000개로 나누어져 있다는 것을 다시 알 수 있다.
즉, 총 50,000개의 리뷰 문장으로 이루어져 있다는 뜻이다.
# 두 문장의 단어의 수 각각 출력
print(len(train_input[0]))
print(len(train_input[1]))
그럼 이 수많은 리뷰 중에서도 훈련 데이터셋의 첫번째 리뷰와 두 번째 리뷰가 몇 개의 토큰(Token)으로 이루어져 있는지 출력해보겠다.
문장에서 '분리된 단어'를 토큰(Token)이라고 부르며, 하나의 리뷰 샘플은 여러 개의 토큰으로 이루어져 있고 1개의 토큰이 하나의 타임스탬프에 해당한다.
ex) Sentence : He loves her cat -> Token : 'He', 'loves', 'her', 'cat'
영어의 경우 문장을 모두 소문자로 바꾸고 구둣점을 삭제한 다음 공백으로 구분하며,
한글의 경우 조사가 발달되어 있어 공백만으로는 구분이 어렵기 때문에, 형태소 분석을 통해 토큰을 만들어낸다.

첫 번째 샘플은 218개의 토큰, 두 번째 샘플은 189개의 토큰으로 이루어져 있다.
여기서 하나의 리뷰가 하나의 샘플을 의미한다.
print(train_input[0])
그럼 샘플은 어떻게 이루어져 있을까?
위 코드를 입력하고 출력해보자.

출력된 화면을 보면 리뷰 샘플의 토큰이 여러 개의 정수로 이루어져 있었다.
이렇게 숫자로 이루어져 있는 이유는 신경망에 텍스트 자체를 전달하지 않기 때문이다.
그 이유는 컴퓨터 내부에서 처리하는 데이터는 모두 숫자이지, 문자 데이터가 아니기 때문이다.
IMDB 리뷰 데이터셋은 이미 리뷰를 각 단어마다 고유한 정수를 부여해놓은 상태이다.
예를 들면, 아래 표와 같다.
| 단어(Word) | He | loves | her | kitty | cat |
| 고유 정수 | 10 | 14 | 20 | 5 | 13 |
이런식으로 각 단어마다 고유한 정수가 부여된 것이며,
위에 출력된 샘플의 정수 값들도 사실상 모두 여러 개의 단어로 이루어진 문장이라는 것이다.
단, 이미 사용하는 0 ~ 3까지의 고유 정수값이 있는데, 여기서 알아야 할 숫자 2는 어휘 사전에 없는 단어를 뜻한다.
조금 더 구체적으로 알아보기 위해 아래 코드를 입력하고 실행해보자.
print(train_input[0])
word_to_index = imdb.get_word_index()
index_to_word={}
#0, 1, 2, 3은 특별 토큰이기 때문에 3을 더해서 배열에 저장
for key, value in word_to_index.items():
index_to_word[value+3] = key
# 0 : 패딩 토큰
# 1 : 문장 시작 토큰
# 2 : 미확인 토큰
for index, token in enumerate(("<pad>", "<sos>", "<unk>")):
index_to_word[index]=token
print(' '.join([index_to_word[index] for index in train_input[0]]))
| 숫자 표현 | 문자 표현 |
| 1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 458, 2, 66, 2, 4, 173, 36, 256, 5, 25, 100, 43, 2, 112, 50, 2, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 2, 2, 17, 2, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2, 19, 14, 22, 4, 2, 2, 469, 4, 22, 71, 87, 12, 16, 43, 2, 38, 76, 15, 13, 2, 4, 22, 17, 2, 17, 12, 16, 2, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2, 2, 16, 480, 66, 2, 33, 4, 130, 12, 16, 38, 2, 5, 25, 124, 51, 36, 135, 48, 25, 2, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 2, 15, 256, 4, 2, 7, 2, 5, 2, 36, 71, 43, 2, 476, 26, 400, 317, 46, 7, 4, 2, 2, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2, 56, 26, 141, 6, 194, 2, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 2, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 2, 88, 12, 16, 283, 5, 16, 2, 113, 103, 32, 15, 16, 2, 19, 178, 32 | <sos> this film was just <unk> <unk> <unk> <unk> story direction <unk> really <unk> the part they played and you could just <unk> being there <unk> <unk> is an amazing actor and now the same being director <unk> father came from the same <unk> <unk> as <unk> so i loved the fact there was a real <unk> with this film the <unk> <unk> throughout the film were great it was just <unk> so much that i <unk> the film as <unk> as it was <unk> for <unk> and would recommend it to everyone to watch and the <unk> <unk> was amazing really <unk> at the end it was so <unk> and you know what they say if you <unk> at a film it must have been good and this definitely was also <unk> to the two little <unk> that played the <unk> of <unk> and <unk> they were just <unk> children are often left out of the <unk> <unk> i think because the stars that play them all <unk> up are such a big <unk> for the whole film but these children are amazing and should be <unk> for what they have done don't you think the whole story was so <unk> because it was true and was <unk> life after all that was <unk> with us all |
숫자로 표현된 샘플 데이터를 문자로 변환시킨 결과이다.
각 단어마다 고유한 정수값이 부여되어 있기 때문에 문자로 표현이 가능한 것이다.
이처럼 IMDB리뷰 데이터셋은 각 고유한 정수로 단어를 표현하고 있다.
이제 입력 데이터에 대해 모두 알아보았으니, 타겟 데이터에 대해서도 알아보도록 하자.
print(train_target[:20])

우리가 모델을 만들려고 하는 이유는 리뷰가 긍정적인 내용인지, 부정적인 내용인지 판단하기 위해서이다.
그러면 이진 분류로 생각할 수 있으므로 타겟값은 0(부정)과 1(긍정)로 나누어진다.
from sklearn.model_selection import train_test_split
train_input, val_input, train_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
이제 데이터를 살펴보았으니, 전체 훈련 세트에서 검증 세트를 떼어 놓도록 하겠다.
전체 훈련 세트가 25,000개였으므로 20%를 떼어 놓으면 20,000개, 5,000개로 나누어질 것이다.
import numpy as np
import matplotlib.pyplot as plt
lengths = np.array([len(x) for x in train_input])
plt.hist(lengths)
plt.xlabel('length')
plt.ylabel('frequency')
plt.show()
모델 훈련을 위해 각 단어를 모두 하나하나 살펴볼 수 없기 때문에 히스토그램을 통해
샘플별로 단어의 개수가 얼마나 이루어져 있는지 간략적으로 살펴보도록 하자.

결과를 보면 대부분의 리뷰 길이는 300 미만임을 알 수 있으며, 어떤 리뷰는 1,000개가 넘는 단어로 이루어져 있기도 한 듯하다.
이렇게 리뷰마다 단어의 개수가 천차만별이기 때문에, 모델을 훈련시킬 때 사용할 단어 길이를 통일시켜 줄 필요가 있다.
해당 예제에서는 단어 개수를 '100'으로 맞출 것이다.
단어의 개수가 100보다 작은 경우에는 샘플을 0으로 채우고, 100을 넘는 경우에는 단어를 잘라내는 전처리 작업을 해야 한다.
직접 하려면 복잡한 일이지만, 다행히도 케라스에서는 시퀀스 길이를 맞춰주는 pad_sequences() 메소드를 제공해준다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 최대 단어의 수를 100으로 설정
train_seq = pad_sequences(train_input, maxlen=100)
val_seq = pad_sequences(val_input, maxlen=100)
print(train_seq.shape)
pad_sequences() 메소드의 매개변수 max_len을 100으로 설정하여 훈련 데이터와 검증 데이터의 최대 단어 개수를 100개로 지정해주고,
훈련 데이터의 크기만 출력해보겠다.

20,000개의 샘플 데이터가 모두 100개의 단어로 통일되어 2차원 배열을 이루고 있다.
데이터 전처리까지 마쳤으므로 이제는 순환 신경망 모델을 만들어보자.
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(8, input_shape=(100, 500)))
model.add(keras.layers.Dense(1, activation='sigmoid'))
케라스에서는 여러 종류의 순환층 클래스를 제공하는데, 그중에서도 가장 간단한 SimpleRNN 클래스를 사용할 것이다.
IMDB 리뷰 문제는 이진 분류임로 마지막 출력층은 1개의 뉴런을 가지며, 시그모이드 함수를 사용해야 한다.
또한, SimpleRNN 클래스의 매개변수 input_shape를 살펴보면 (100, 500)으로 지정하였는데,
앞의 100은 각 샘플의 길이를 뜻하고, 500은 맨 처음에 설정한 빈도수가 높은 단어의 개수를 뜻한다.
값을 500으로 설정하는 이유는 원-핫 인코딩을 사용할 것이기 때문이다.
여기서 원-핫 인코딩이란, 예제의 500개의 단어들 중 딱 1개의 단어만 1이고, 나머지는 0으로 이루어진 배열에 데이터를 구성하여 고유 단어를 구분하는 인코딩 방법이다.
마치 아래의 그림과 같다.

Rome이란 단어는 첫번째 요소가 1이고, Paris는 두 번째 요소가 2이며 아래 단어들도 각각 고유한 인덱스에서 1을 가지고, 나머지 요소들은 모두 0 임을 알 수 있다.
케라스에서는 정수 배열을 입력하면 원-핫 인코딩된 배열을 반환해주는 to_categorical() 메소드를 제공한다.
train_oh = keras.utils.to_categorical(train_seq)
val_oh = keras.utils.to_categorical(val_seq)
print(train_oh.shape)
print(train_oh[0][0][:12])
print(np.sum(train_oh[0][0]))

훈련 데이터셋과 검증 데이터셋을 모두 메소드에 입력하여 반환된 배열의 크기와 인코딩 결과를 출력해보면,
20,000개의 샘플이 100개의 단어로 이루어져 있으며, 정수 하나마다 500차원의 배열로 변경되었음을 알 수 있다.
이렇기 때문에 SimpleRNN 클래스의 input_shape 매개변수 값을 (100, 500)으로 지정한 것이다.
또한, 앞의 12개의 원소를 출력해보면 여러 원소들 중 11번째 원소만 1 임을 확인할 수 있다.
혹시 모르기 때문에 나머지 원소도 모두 0인지 확인하기 위해 sum() 메소드로 모든 원소의 값을 출력해보았고, 결과적으로 딱 1개의 원소만 1이었다.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-simplernn-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_oh, train_target, epochs=100, batch_size=64,
validation_data=(val_oh, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
이제 본격적으로 순환 신경망을 훈련시켜보도록 하자.
해당 예제에서는 RMSprop을 옵티마이저로 사용하며 학습률을 0.0001로 지정하였고, 에포크 횟수를 100으로 늘렸으며 배치 크기는 64개로 설정하였다.
또한, 콜백으로 체크포인트와 조기 종료를 추가하였다.

검증 손실이 점점 줄어들다가 다시 증가하는 순간이 보인다.
EalryStopping의 patience를 3으로 설정하였기 때문에 3번까지 지켜보다가 적절한 시기에 조기종료되었다.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
우리가 만든 모델의 손실 값을 시각화해보기 위해 위 코드를 입력하고 실행시켜보자.

모델의 손실 곡선을 그려본 결과 훈련 손실은 꾸준히 감소하고 있지만 검증 손실은 스무 번째 에포크에서 감소가 둔해지고 있다.
이렇게 순환 신경망을 적용시켜 IMDB 리뷰 데이터를 분류하는 모델을 만들어보는 작업을 수행해보았다.
하지만 여기서 한 가지 단점을 생각해볼 수 있다.
원-핫 인코딩으로 데이터를 변환하면, 토큰 1개를 500차원으로 늘리는 것이기 때문에 입력 데이터의 크기가 매우 커진다는 점이다.
따라서 다른 처리 방법인 단어 임베딩(Word embedding)을 적용해볼 것이다.
단어 임베딩은 아래 그림처럼 각 단어를 고정된 크기의 실수 벡터로 바꾸어 준다.

따라서 원-핫 인코딩에 비해 훨씬 의미 있는 값을 사용할 뿐만 아니라, 데이터의 크기도 훨씬 줄어들 것이다.
케라스에서는 Embedding 클래스로 임베딩 기능을 제공해준다.
이 클래스는 다른 층처럼 모델에 추가하면 처음에는 모든 벡터가 랜덤 하게 초기화되지만 훈련을 통해 데이터에서 좋은 단어 임베딩을 학습한다.
model2 = keras.Sequential()
model2.add(keras.layers.Embedding(500, 16, input_length=100))
model2.add(keras.layers.SimpleRNN(8))
model2.add(keras.layers.Dense(1, activation='sigmoid'))
Embedding 클래스의 첫 번째 매개변수는 어휘 사전의 크기이다.
이전과 동일한 가장 빈도수가 높은 단어의 개수 500개를 뜻하는 것이다.
또한, 두 번째 매개변수 16은 임베딩 벡터의 크기이다.
확실히 원-핫 인코딩에 비해 훨씬 작은 크기의 벡터를 사용하고 있다.
마지막으로 세 번째 매개변수 100은 토큰의 개수(시퀀스 길이)이다.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model2.compile(optimizer=rmsprop, loss='binary_crossentropy',
metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-embedding-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model2.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
모델 훈련 과정은 이전과 동일하므로 바로 훈련을 진행해보도록 하겠다.

출력 결과를 확인해보면 원-핫 인코딩을 사용한 모델과 비슷한 성능을 내고 있지만,
가중치 개수가 훨씬 작고 훈련 세트의 크기도 훨씬 줄어들었다.
마지막으로 훈련 손실과 검증 손실을 그래프로 출력해보자.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()

검증 손실이 계속해서 감소되지 않아 모델이 훈련을 적절히 조기 종료하였다.
반면 훈련 손실은 계속 감소하는 경향을 확인할 수 있다.
이번 글에서는 이전의 이론 포스팅에서 다루었던 순환 신경망의 개념을 실제 모델로 구현해보는 작업을 해 보았다.
그 과정에서 입력 데이터를 0과 유일한 1로 변환해주는 원-핫 인코딩을 사용해보았고,
각 단어를 실수로 이루고 있는 Embedding 층을 추가해보기도 해보았다.
다음 포스팅에서는 LSTM과 GRU 모델을 사용하여 더 복잡한 문제에 적용하는 고급 순환층을 다루어보도록 하겠다.
전체 소스 코드 :
https://colab.research.google.com/drive/1g8nBTu_ubTwmBSiKazzSPyo2Yh0yMOMs?usp=sharing
👍클릭으로 구독하기👍
(이해가 다소 힘들거나, 틀린 부분이 있다면 댓글 부탁드리겠습니다! 😊)
💖도움이 되셨다면 '구독'과 '공감' 부탁드립니다!💖